



 +7 (495) 280-11-23
+7 (495) 280-11-23 Пн - Пт: 9:00 - 19:00
Пн - Пт: 9:00 - 19:00
Есть множество подходов к организации инфраструктуры аналитики больших данных. Зависят эти походы в частности от того, каков объем этих данных, допустима ли задержка (и какая) между поступлением данных и их отображением на аналитической панели, в каком формате хранятся исходные данные: sql таблицы, NoSQL, текстовые лог файлы, csv или xlsx.
Исходя из этого можно нарисовать множество схем начиная от простых безкластерных до серъезных кластерных решений. От этого зависит, какие программные продукты использовать в качестве хранилища файлов, ETL, аналитической СУБД.
В этой статье разберем два основных подхода.
Инструменты для небольшого количества данных
Вариант первый - мы работаем с небольшим набором данных, скажем, до 20 млн строк в таблице. В этом случае вполне можно обойтись следующим opensource ПО:
СУБД: PostgreSQL
ETL: Apache NiFi
OLAP: Clickhouse
Визуализация: Apache SuperSet
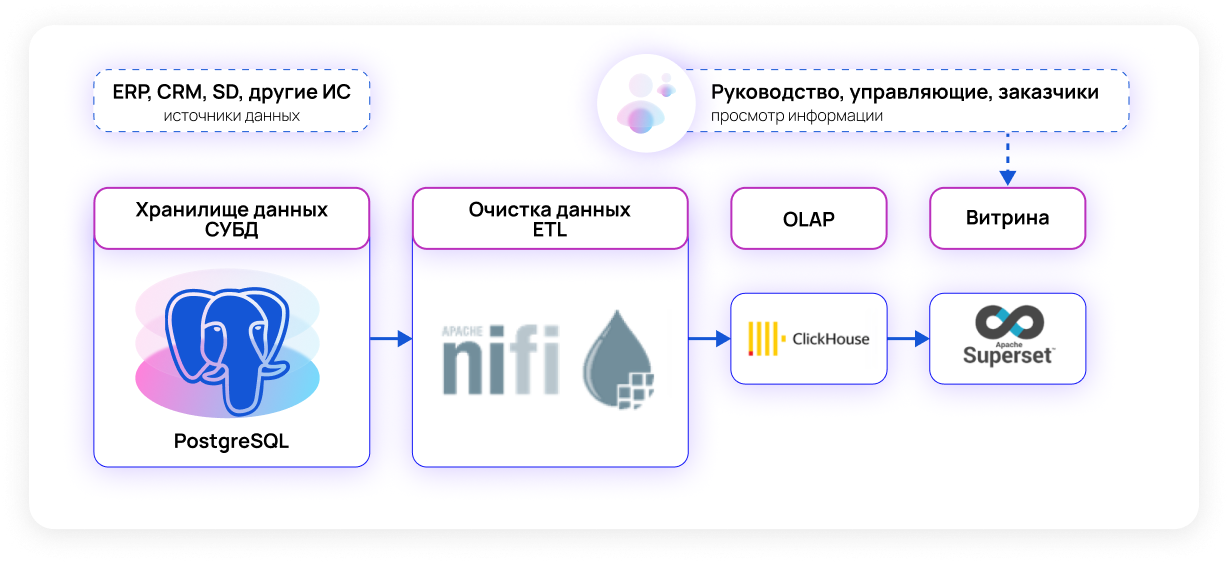
Apache NiFi – надежный и легкий в освоении инструмент для создания процессов преобразования и передачи данных (ETL), но требователен к системным ресурсам.
Clickhouse хорошо масштабируется и отлично работает как в кластере, так и на обычной виртуалке с небольшими системными ресурсами. Поэтому он используется в схемах для практически любого объема данных.
Инструменты анализа данные в реестре РФ
Если вам необходимо, чтобы ПО было в реестре российского ПО, используйте продукты от компании Arenadata. Все вышеперечисленное, за исключением SuperSet, есть у них под другими названиями и с достаточно удобным установщиком Artenadata Cluster Manager.
Если допускается использование платного ПО из реестра российского ПО, то возможно решение на основe PostgresPro и Visiology:
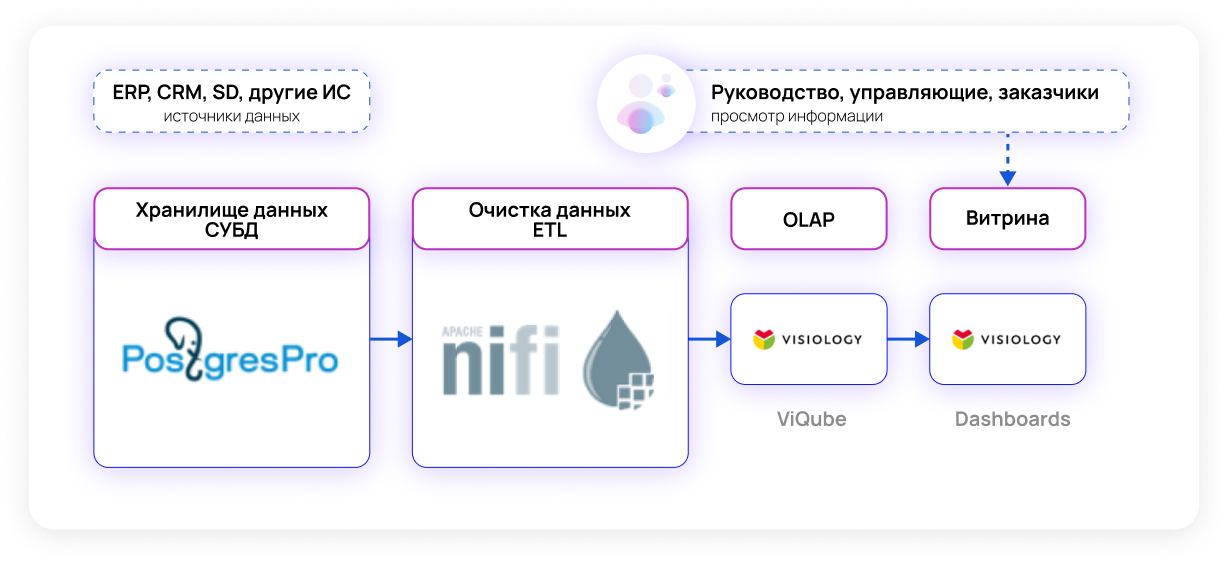
Также можно использовать enterprise версии от Arenadata.
Такую схему мы внедрили в Московском метрополитене, за исключением того, что вместо PostgresPro используется OpenSource PostgreSQL.
Инструменты для большого объема данных
При необходимости вести аналитику для действительно большого объема данных, начиная от 1 Тб, а также при необходимости отображать аналитику близко к реальному времени, не обойтись без серьезных кластерных платформ и решений для них.
Схема платформы для аналитики в этом случае может быть следующей:
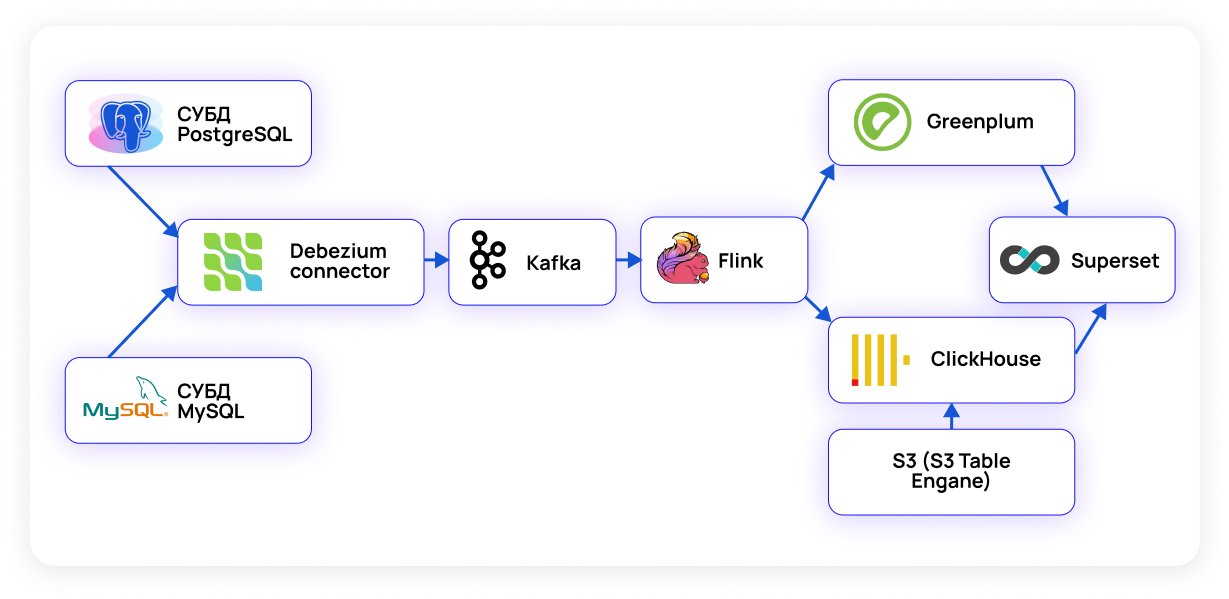
В качестве источников данных тут выступают СУБД PostgreSQL, MySQL или иные СУБД, а также хранилище S3.
Debezium – это по сути набор коннекторов для разных СУБД, позволяющий отслеживать и передавать измененные данные (CDC – change data capture) с низкой задержкой и высокой надежностью, поскольку он построен поверх Apache Kafka.
Для преобразования данных, то есть в качестве ETL целесообразно использовать Apache Flink и/или Apache Spark, имеющий высокую скорость и позволяющий обрабатывать данные в режиме времени, близком к реальному. Однако также можно применить Kafka Stream, выполняющий ту же функцию и близкий java разработчикам.
В качестве аналитической СУБД имеет смысл использовать СУБД Greenplum в качестве data warehouse, а также Clickhouse для работы с потоком данных и построения аналитических отчетов в реальном режиме времени.
Компания КСК ТЕХНОЛОГИИ имеет большой опыт визуализации аналитической отчетности с помощью Pentaho Reporting.




